Proto: A programming language for generative biology
A conversation with Brian Hie, Aditi Merchant, Daniel Guo, and Ben Viggiano

For years, biological research has relied on assembling natural components through trial-and-error or screening thousands of candidates until something worked. While powerful AI models for protein design, RNA engineering, and gene regulation have the potential to accelerate this process, they remain isolated in computational silos, out of reach for many experimental biologists. Today, the Laboratory of Evolutionary Design, led by Brian Hie, is releasing Proto (https://www.biorxiv.org/content/10.64898/2026.06.22.733870), a framework that integrates these diverse AI tools to enable complex, multi-modal biological design.
The name "Proto" captures the project's vision as foundational design infrastructure bridging computation and biology. It composes specialized AI models and bioinformatics tools, each predicting different aspects of biological structure or function, to produce sequences that satisfy multiple objectives simultaneously. Unlike previous approaches that stitch together predefined parts with intuition, heuristics, or trial-and-error, Proto specifies high-level functional objectives, allowing models to act as creative partners with biologists to program biological designs.
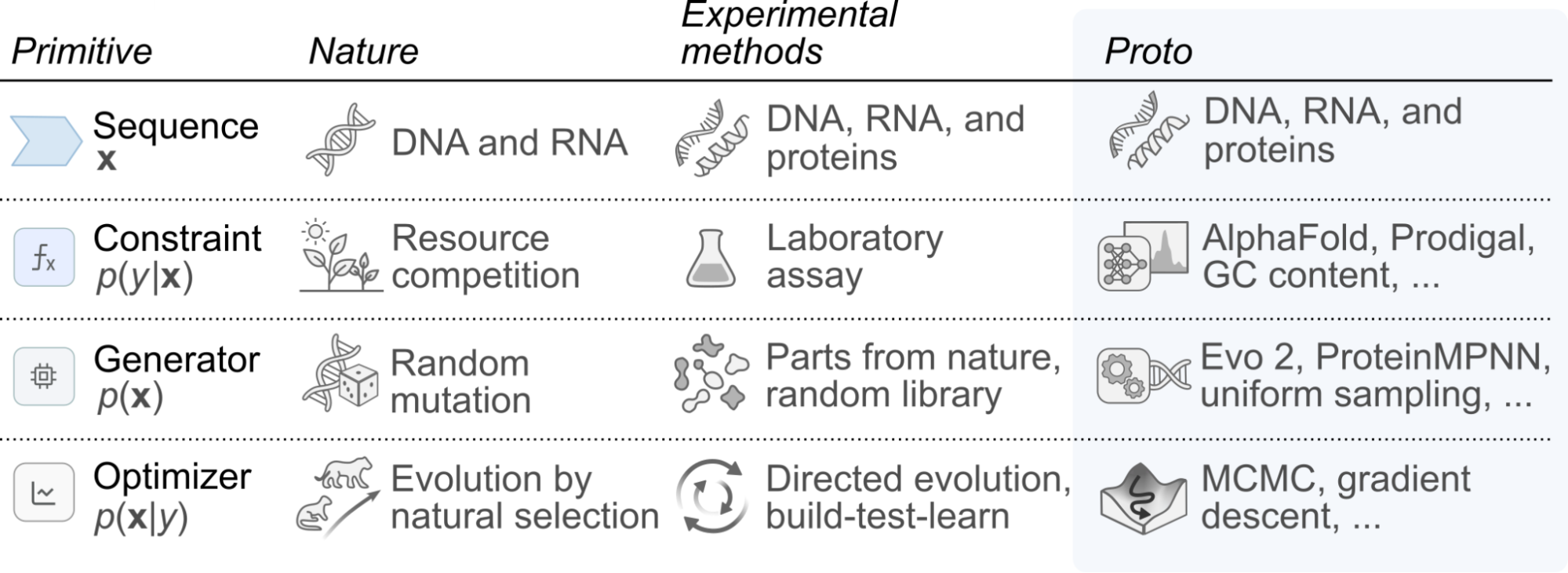
At its core, Proto distills biological design into four abstract primitives: sequences that define molecular strings, generators that propose candidates, constraints that score these candidates, and optimizers that steer generation toward desired functions. Proto compiles the high-level constraints specified by a user into a unified energy function that mathematical optimizers seek to minimize, enabling multi-objective design across DNA, RNA, proteins, ligands, and their interactions. Critically, Proto defines modularity at a functional or semantic level rather than at the sequence level, relying on deep generative models to design de novo sequences that satisfy specified constraints.
Testing this approach on synthetic promoter-repressor pairs, Proto achieved functional designs with experimental testing of only tens of candidates, representing leading success rates for de novo design of DNA-protein interactions. Proto was also able to design cell-line-specific alternative splicing after testing only tens of designs; in contrast, previous methods tested thousands of designs to obtain functional results.
The platform democratizes generative biology through both a drag-and-drop graphical web interface for experimentalists and a Python API for computational users seeking fine-grained control. Recognizing the rapid advancement of AI coding agents, the authors deliberately designed Proto to serve as a programming language that both human scientists and AI agents could use fluently. The team has made their methods open source, releasing Proto as accessible software infrastructure and anticipating rapid integration of newly developed models by the research community.
In this discussion, four of the co-authors explore the computational innovations behind Proto, how it bridges AI and wet-lab biology through accessible interfaces, its current capabilities and limitations, and its potential to even the playing field in complex biological design. The conversation includes:
- Brian Hie (X: @BrianHie), an Assistant Professor of Chemical Engineering at Stanford University, the Dieter Schwarz Foundation Stanford Data Science Faculty Fellow, and Arc Institute Innovation Investigator in Residence;
- Aditi Merchant (X: @aditimerch), a Stanford Bioengineering PhD student;
- Daniel Guo (X: @dan_guo_), a Stanford Computer Science Masters student;
- Ben Viggiano (X: @bviggiano_13), a Stanford Biomedical Data Science PhD student.

What problems were you facing that inspired you to develop Proto?
Aditi Merchant: Biological AI models have gotten significantly better at generating sequences that might perform specific functions, but for most of the broader biological research community, it's not always clear how to best leverage them for something they're actually working on. Proto started as an idea to make generative biological design more accessible. Most of these models exist in silos. One may be really good at protein design, another at DNA, and another at predicting sequence properties, so when you combine them, you get something far more powerful than any single model alone. It allows you to generalize to a much broader range of design objectives.
Daniel Guo: We originally designed Proto with wet lab biologists in mind--people who may not have as much computational experience, but who know the biological problems best. As the project progressed, we realized that in addition to making the front-end user interface, we could also make a huge difference by creating high-quality open-source infrastructure to solve some of the more tedious technical aspects of using the models themselves. A side effect of this was that we found that this also significantly helps coding agents successfully utilize the setup and utilize these tools, which even further improved usability.
If combining these models adds so much value, why wasn't anyone doing it?
Daniel Guo: The current ecosystem of biological AI tools is also not designed for integrated design campaigns. These models get released as independent artifacts with different software dependencies, hardware requirements, and input/output conventions that almost always conflict with each other. That lack of compatibility was a really big issue that we grappled with.
Ben Viggiano: Prior to developing Proto, the first week, sometimes two or three, of every biological design project I worked on went to setup. We had to build a system to call each model we wanted to use, reconcile conflicting dependencies across tools, and balance their resource demands in iterative design loops where efficiency matters across long runs. Worse, a single implementation mistake could quietly produce suboptimal designs, leading to significant lost time and cost for experimentalists before it was discovered and fixed. We built much of our open-source infrastructure around exactly these pain points, drawing on what our own experience suggested would help others and iterating on feedback from friends in other labs at Stanford.
Inside the tool layer of the framework is a dependency isolation system, so each tool runs within its own virtual environment through subprocesses dispatched from the main process. On top of that, we handle device management and parallelization so users can maximize the hardware they have access to. We also documented the structure and function of every input, config, and output in detail, so the framework doubles as an educational resource for newcomers learning how these models work and fit together rather than just a black box that runs them.
Daniel Guo: Our hope is that these implementations reduce friction and let computational biologists skip this stage of a project entirely, so they can focus on the more important aspects of their work. In addition, our goal is to create what amounts to a trusted community standard for quickly implementing and running models across a wide range of hardware, to improve reproducibility and avoid the errors that creep in during setup.
Proto reduces any AI-driven biological design campaign to four primitives: sequences, constraints, generators, and optimizers. How did you arrive at those?
Daniel Guo: We conducted interviews with various researchers across computational and wet lab backgrounds, asking what made sense to break this type of work down into common abstractions. The common thread is that every design campaign has to produce a sequence, evaluate whether it is desirable, generate candidates, and improve on them.
Brian Hie: The primitives are theoretically grounded and also practically useful as an educational tool. To a biologist, antibody design and promoter design can look completely different from each other. But if you think through both using the same four primitives, you can immediately locate where in the design process you are working.
Aditi Merchant: There is also a nice analogy to how natural evolution works. You have a sequence, some form of evolutionary pressure acting like a constraint, random mutations as proposals, and optimization toward fitness. This is not only something that we want to do with biological design but also something that nature has done for over millions of years.
Where does Proto fit in the history of attempts to program biology?
Aditi Merchant: Traditionally, biological design has been centered around taking natural components and assembling them together, testing combinations, and optimizing over many iterations. That approach has worked very well, and a lot of synthetic biology's greatest successes and breakthroughs have come from repurposing natural systems. But as we move toward models that can understand more intrinsic properties of biology, we can start designing things outside the scope of what you would easily find in nature.
Brian Hie: There is a long-standing goal in biological research to program living systems the way you program a computer. Previous approaches to programming biology involve tasks like fusing two proteins together into a chimera, or writing the literal sequence of a guide RNA. This works fine for simple systems, but more complex biological design resists that approach. Everything is globally entangled. There is no neat modular component that you can stack like Legos.
What Proto does differently is move the modularity up a level. Instead of composing DNA sequences according to rules, you specify what you want at a conceptual level, and then generative models translate that into sequences. Modularity happens at the level of concepts, not at the level of sequences.
The intron design experiments were your first attempt to show Proto working on a new biological objective. What were you trying to demonstrate, and what did you find?
Aditi Merchant: Cell-type-specific targeting has been a hallmark goal in biological design. There are established approaches, but alternative splicing is relatively underexplored as a mechanism. We decided to design intronic sequences where one cell line would process the intron normally, while the other would produce a non-functional protein.
We were able to show that layering a predictive model on top of a generative model, in combination with an optimizer loop, could produce sequences that fulfill a more complex biological objective than any single model could handle alone. The sequences we designed targeted several cell line combinations--a brain cell line versus blood, liver versus blood--using AlphaGenome and SpliceTransformer as our constraint models, and were validated experimentally in human cell lines.
Brian Hie: What we found in several cases was cryptic splice sites, meaning the model engineered alternative splice sites to reduce splicing at the expected design sites. It used a biological mechanism to achieve a high-level specification in a way that I, as a human researcher, did not originally anticipate. It demonstrates the value of specifying things at a high level because there are actually multiple biological paths to reach the objective.
What made the promoter-repressor design a more complex test for Proto than the intron experiments?
Aditi Merchant: The intron work was a single modality--an RNA sequence against a splicing constraint--while promoter-repressor design requires two modalities simultaneously. You are designing a DNA sequence and a protein sequence that have to interact specifically with each other, but the protein should not interact with other DNA in the cell, and the DNA should not cause other transcription factors to bind it. Everything should be orthogonal to what is naturally in the cell while still functioning as an on/off switch. Success also requires the repressor to dimerize before it can bind the promoter, which tightens the constraints on both components.
Brian Hie: What we found was that composing many existing structure predictors and protein-DNA interface models within Proto was sufficient to achieve strong experimental success rates without training any task-specific model for protein-DNA codesign. To put the success rates in context, there has been work on simpler versions of this task--a single protein binding to DNA, no cooperativity required--and our results are comparable. We got there testing tens of designs in the lab, not doing high-throughput screening.
What does Proto do well, and where does it have room to improve?
Ben Viggiano: What it does best is make AI models for biology more accessible and usable to a wider audience. Being able to import something and have it work immediately, and then have it composable with everything else in the framework, is not a small thing. At the end of the day it will be experimental biologists who take these designs to the bench.
Aditi Merchant: At the same time, we are fundamentally limited by the models available. If you want to design for an objective where no good model exists, that is the end of the road. You can try, but if the model is not there or high quality enough, you aren't going to see experimental success. That is also what makes it exciting because as models get better, Proto gets better with them.
The pipe dream is being able to tell Proto "generate me a cell-type-specific therapeutic," run it, and be reasonably confident that you will get experimental hits, but we have huge strides to go to get there. Getting there will take huge improvements in model quality and making the interface easy enough that the specification of the task itself is not the bottleneck.
Brian Hie: Another caveat is that sometimes Proto is slow. Depending on the optimizer, a run can take half an hour or more. That is because Proto uses inference-time search, so you are actually running the model for a long time before committing to an answer. Finding better optimizers, maybe more universal ones, is something we are also working on.
What's next for Proto?
Aditi Merchant: We hope it becomes a growing ecosystem rather than a static release. We hope that we have streamlined the process enough to make it easy for any lab hoping to share their latest tool or model to our repository directly. We are genuinely excited to see whether the community starts contributing their own models.
Daniel Guo: The vision is that Proto becomes a unified infrastructure--the thing researchers reach for whenever a new biological AI model comes out, either to plug it in themselves or to find out if it is already there. As the field continues to snowball and coding models get better, a lot of this integration can be more streamlined. We hope more people in the community will get involved and contribute to the codebase.
Is there anything you want the community to understand about what this is and is not?
Aditi Merchant: I really do want to emphasize that Proto is not meant to replace experiments or traditional biological design methods. It is meant to give researchers additional starting points so that when they go to the bench, they can test a small number of well-reasoned candidates rather than screening thousands of designs hoping something works. As experimental biology advances and models improve, the two should reinforce each other.
Ben Viggiano: What we want is to spare researchers the sleepless nights we had figuring out dependencies and infrastructure and writing all the glue code. So they can just use these tools and do real science.
Merchant, A.T., Guo, D., Viggiano, B., Brennan-Almaraz, L., Hur, E., Mai, T., Yin, P., King, S.H., Ashley, E.A., & Hie, B.L. (2026). A high-level programming language for generative biology with Proto. bioRxiv. https://doi.org/10.64898/2026.06.22.733870
Get started with Proto: https://proto.evodesign.org